PLAYBOOK · LOCAL AI
Local AI for Enterprise: from Ollama experiments to governed production
Most enterprises start local AI with Ollama, vLLM, or llama.cpp — and hit the same wall. The model runs. Everything around it doesn't: no routing, no governance, no audit trail, no access control, no monitoring. This playbook maps the path from a local model experiment to a production-grade sovereign AI stack.
Open-weight models are genuinely enterprise-ready in 2026. Llama 3, Mistral, Qwen 2.5, Phi-3 — these models can replace cloud APIs for a wide class of business tasks at a fraction of the cost. The challenge is not inference anymore. The challenge is everything above the inference layer: who can call the model, which prompts govern it, how calls are logged, how it routes to a stronger model when it's insufficient, how RAG grounds it in private knowledge. VDF AI provides that layer. Your Ollama, vLLM, or llama.cpp runtime stays exactly where it is.
The problem
Local models run. Production doesn't.
Most teams can get Ollama or vLLM running in an afternoon. What they can't get running is everything around it: who can call the model, which prompt templates govern it, how costs are tracked, how it routes to a cloud model when the local one is insufficient, how the compliance team gets an audit trail.
The VDF AI approach
Register your runtime. Inherit enterprise governance.
VDF AI registers your Ollama, vLLM, or llama.cpp endpoint as a Model Source in the SEEMR router. From that point it's governed: access control, routing policies, audit logging, agent orchestration, and RAG grounding — without replacing anything that's already running.
WHY THIS MATTERS NOW
The inference problem is solved. The governance problem isn't.
Open-weight models crossed a capability threshold in 2025. A Llama 3.1 70B or Qwen 2.5 72B model running on enterprise hardware can replace a cloud frontier model for a wide class of business tasks — summarization, classification, document extraction, code review, drafting. Ollama and vLLM made that accessible. The limiting factor is no longer the model.
The limiting factor is the layer above the model. Security teams block local AI deployments because there's no access control. Compliance teams block them because there's no audit trail. Finance teams block them because there's no cost tracking. Operations teams block them because there's no routing when the local model is saturated or insufficient.
THE LOCAL AI RUNTIME LANDSCAPE
What each runtime is built for
Single-command local inference, OpenAI-compatible API, model downloads built in. Excellent for developer workstations, proof-of-concepts, and moderate-traffic on-prem servers. Stops at the inference layer.
High-throughput production serving with PagedAttention and continuous batching. 2–4× better GPU utilization than naive serving. Right for multi-user GPU clusters at production scale. Does not provide governance or routing.
GGUF quantized model inference on CPU, Apple Silicon, or low-power hardware. Near-zero hardware requirements. Right for air-gapped servers without GPUs, edge devices, and moderate traffic with quantized models.
OpenAI-compatible API gateway supporting multiple backends (llama.cpp, whisper, stable diffusion). Good for unified local API surfaces across model types.
Developer GUI for browsing, downloading, and testing models. Exposes an OpenAI-compatible local server. Best for evaluation and experimentation; not designed for multi-user production workloads.
Sits above all runtimes. Registers any OpenAI-compatible endpoint as a Model Source. SEEMR routes across them by capability, cost, latency, energy, and policy. Adds agent orchestration, RAG, access control, and audit trail.
THE GOVERNANCE GAP
What local runtimes don't provide — and why it blocks production
Access control
Ollama, vLLM, and llama.cpp expose unauthenticated HTTP endpoints by default. Any process that can reach the port can call any model. No per-user or per-team restrictions. VDF AI adds RBAC and identity-aware access policies.
Audit trail
No runtime logs who called the model, which prompt was used, or what the output was. For regulated industries — banking, healthcare, government — that is a compliance blocker. VDF AI logs every call with full context.
Routing intelligence
A local runtime serves one model on one machine. There is no intelligence that says "this task needs a 70B model" or "this task should overflow to a cloud API because the local model is saturated." SEEMR provides that.
Agent orchestration
Local runtimes do not chain model calls into multi-step workflows, call external tools, perform RAG retrieval, or implement human-in-the-loop approval. VDF AI Networks handle all of that.
RAG & knowledge
No runtime includes document ingestion, vector indexing, or semantic retrieval. Grounding model outputs in private enterprise knowledge requires a separate RAG layer. VDF AI Data provides that as part of the platform.
Cost & energy tracking
Without a platform layer, there is no visibility into which team is spending what on AI. SEEMR tracks cost and energy per model, per task, and per department — and can enforce budgets.
REFERENCE ARCHITECTURE
The enterprise local AI stack — seven layers
dev · edge
GPU · prod
CPU · air-gap
overflow
VDF AI governs layers 2–5 (top to bottom). Ollama, vLLM, and llama.cpp are registered as Model Sources at layer 6. Cloud APIs sit alongside local runtimes as optional overflow sources.
PLAYBOOK · STEP BY STEP
From local experiment to governed production
Install VDF AI on-prem
Deploy the VDF AI stack via Docker Compose. Agent Hub, Data Service, Networks, Chat, and Portal come up with sensible defaults. See the Day 1 quickstart for the detailed install path.
Register your local model endpoints
In the VDF AI model registry, add each local endpoint as a Model Source: your Ollama server (http://ollama-host:11434), vLLM endpoint (http://vllm-host:8000), or llama.cpp server. Specify the model name, capability tags, and cost profile for each. Cloud API keys can be added as additional sources for overflow routing.
Configure SEEMR routing policies
Define routing rules: which task types prefer local models, which tasks can overflow to cloud, which departments are restricted to on-prem sources only. SEEMR evaluates each incoming call against these policies and the registered model capability profiles — routing is dynamic and automatic from this point forward.
Connect your knowledge sources
Register Confluence spaces, SharePoint libraries, GitHub repos, and internal documents in VDF AI Data. The platform ingests, chunks, embeds, and indexes them into pgvector. Every agent and chat session can now retrieve from private knowledge before calling the model.
Build agents and networks
Define agents in VDF AI AgentsHub with intent templates and system prompts. Wire them into Networks in Network Labs — the visual canvas for multi-agent orchestration. Agents call the SEEMR router, not the model directly, so routing and governance are transparent to agent logic.
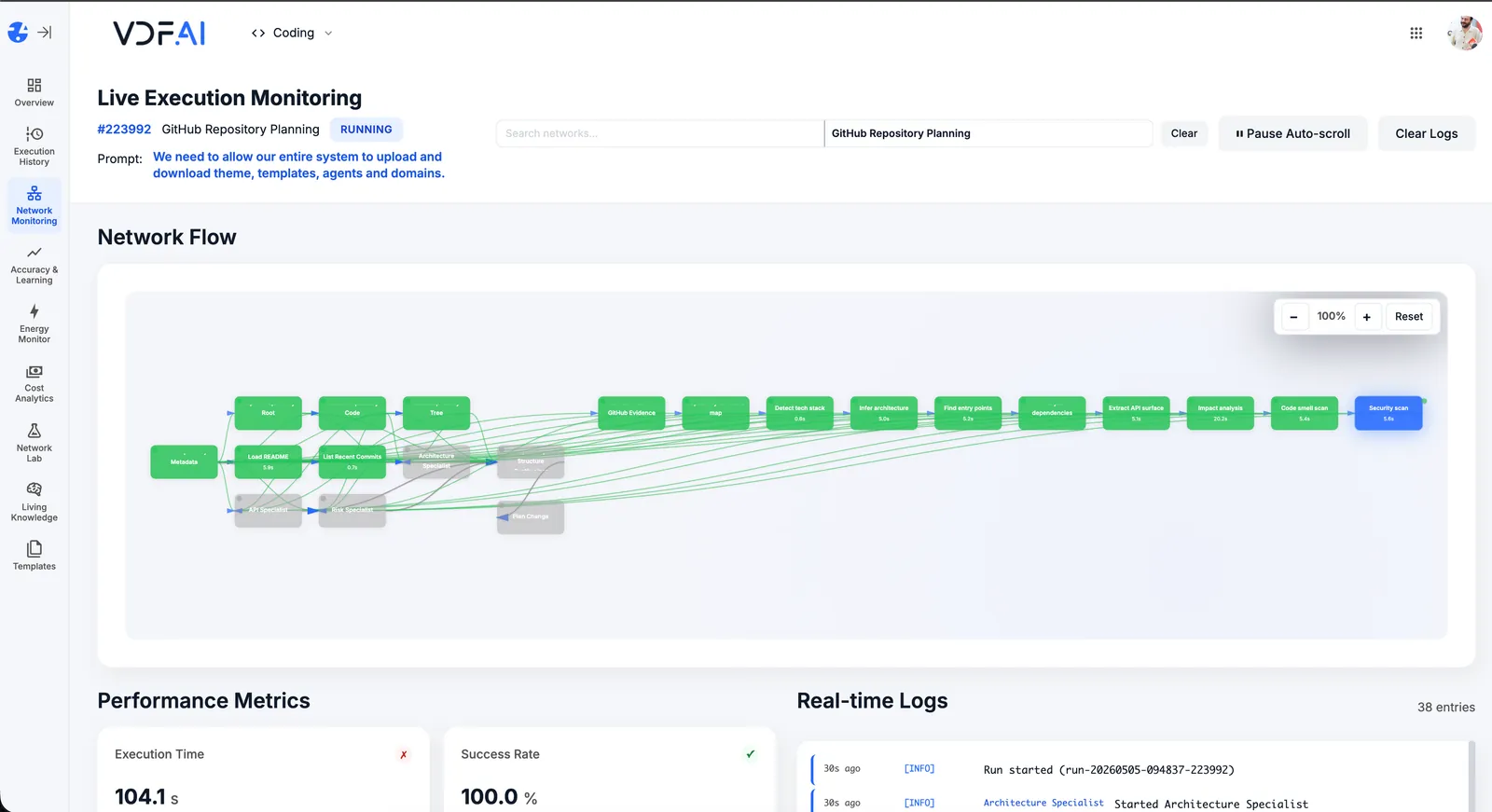
Enable governance and monitoring
Set up RBAC in the portal: which teams can invoke which agents and model sources. Review the Live Execution Monitoring dashboard — every call from every agent is logged with user identity, model used, latency, cost, retrieved context, and output. This is the audit trail that unblocks compliance and security sign-off.
OUTCOMES
What you have at the end of this playbook
Every call to every local model is access-controlled, logged, and policy-checked — regardless of whether it routes to Ollama, vLLM, llama.cpp, or a cloud API.
SEEMR selects the right model for each task at runtime. Routine tasks go to local models; complex tasks escalate; restricted data stays on-prem.
Private knowledge from Confluence, SharePoint, GitHub, and internal documents is indexed and retrieved automatically, grounding every response in enterprise context.
The audit trail, system register, and governance documentation required by the EU AI Act are generated automatically from Live Execution Monitoring data.
Per-department, per-model, and per-task cost tracking. SEEMR enforces budgets — if a department hits its local model cap, overflow to cloud is policy-controlled.
For fully air-gapped deployments: model inference, RAG retrieval, governance, and chat all run on-prem. No token leaves your network for sensitive workloads.
SEEMR REFERENCE
One router for all your model sources
SEEMR is the routing and governance engine at the heart of VDF AI. It treats Ollama, vLLM, llama.cpp, and cloud APIs as interchangeable model sources — selecting the right one for each task based on capability, cost, latency, energy, and data-residency policy. When a local model is upgraded, retired, or replaced, SEEMR adapts automatically. Applications never see the change.
FREQUENTLY ASKED QUESTIONS
What teams ask before shipping this playbook
What is the difference between running Ollama directly and using VDF AI with Ollama?
Running Ollama directly gives you inference. VDF AI with Ollama gives you governance: access control, routing policies, audit logs, agent orchestration, RAG grounding, and cost tracking. Ollama stays where it is — VDF AI registers its endpoint and wraps every call in policy and observability.
Can vLLM and Ollama coexist in the same VDF AI deployment?
Yes. Register both as Model Sources in the VDF AI Router. SEEMR can route different task types to different runtimes: low-latency requests to Ollama, high-throughput batch calls to vLLM, and overflow to a cloud API when both are saturated.
How does SEEMR decide which local model to use for a task?
SEEMR evaluates each task against capability profiles, latency targets, cost budgets, energy settings, and policy constraints. A small summarization task might route to Llama 3.1 8B on Ollama. A complex reasoning task might route to a 70B model on vLLM, or to a cloud frontier model if the local option is insufficient.
Can llama.cpp handle enterprise inference loads?
llama.cpp is CPU-efficient and excellent for quantized models on standard server hardware. It is appropriate for moderate-traffic workloads, edge inference, and air-gapped servers without GPUs. For high-throughput production inference, vLLM on GPU hardware is the recommended serving layer.
What about air-gapped environments?
VDF AI ships as a container bundle with no outbound dependencies at runtime. Register local model endpoints from Ollama, vLLM, or llama.cpp running inside the same network. Zero data leaves your perimeter.
Does VDF AI support LM Studio or LocalAI as model sources?
Any endpoint that exposes an OpenAI-compatible API can be registered as a Model Source. LM Studio and LocalAI both expose that interface — register the endpoint URL and VDF AI treats it like any other model.
RELATED
Continue with related VDF AI patterns



GET IN TOUCH
You Have Questions
Tell us what you’re trying to achieve—governed AI Networks, enterprise RAG, deep integrations, or on‑premise deployment. We’ll help you map the right architecture, security posture, and rollout path. If you’re moving beyond AI pilots and need scalable, auditable execution, reach out—our team is ready to help.