PLAYBOOK · GETTING STARTED
Day 1 — install VDF AI on your hardware, free for two months.
Most "on-prem" AI evaluations stall on infrastructure. This playbook gets you from a clean server to a working VDF AI portal — superadmin created, models registered, first agent ready — in a single afternoon. Two months of the Sovereign tier are on us while you evaluate.
Most "on-prem AI" evaluations stall on infrastructure. Before a single business question can be tested, IT teams spend weeks on Kubernetes plans, model hosting, and identity bridging. VDF AI ships as a small set of containers with sensible defaults: from a clean server to a working portal, superadmin created, models registered, first agent live — in a single afternoon. Two months of the Sovereign tier are on us while you evaluate.
The problem
"On-prem AI" usually means a six-month deployment
Most on-prem stacks need a cluster team, a Kubernetes plan, and an integration army. By the time IT signs off, the business case is stale.
The VDF AI approach
Docker-first, batteries included
VDF AI ships as a small set of containers with sensible defaults. A single compose plan brings up Agent Hub, Data Service, Networks v3, Chat, Portal, and the MCP server. Add models and you're live.
WHY THIS MATTERS NOW
Time-to-first-agent is the real benchmark
AI vendors love to talk about model benchmarks. Engineering leaders should care more about operational benchmarks: how long from sign-off to first agent running on the company's own hardware? For most platforms, that answer is months. For VDF AI, it is hours.
Docker-first packaging, an opinionated compose plan, a single bootstrap command for the superadmin, and a model registry that takes any provider — that is the package. SEEMR governance is in the box from day one; you do not have to "graduate" to it later.
WHAT YOU NEED TO START
Prerequisites for a pilot
Hardware
- Linux server (16+ vCPU, 64 GB RAM recommended)
- Optional: GPU for local model hosting
- 500 GB free SSD for indexes and logs
- Outbound HTTPS to your registry (or air-gap tarball)
Software
- Docker 24+ and Docker Compose v2
- Postgres or use bundled image
- TLS certificates or reverse proxy
- Optional: K8s if you prefer
People
- One sysadmin for install
- One identity admin for SSO (later)
- One product owner to define the first agent
- Optional: an SRE for hardening
REFERENCE ARCHITECTURE
What you'll have by the end of Day 1
:3809
:7001
PLAYBOOK · STEP BY STEP
From docker pull to first agent
Pull the on-prem image bundle
Authenticate to the VDF AI registry, pull the bundle, and verify checksums. Air-gap mode lets you transfer the bundle as a tarball.
docker login registry.vdf.ai
docker pull registry.vdf.ai/vdf-ai/onprem:latest
# air-gapped:
docker save registry.vdf.ai/vdf-ai/onprem:latest -o vdf-ai-onprem.tarCompose up the stack
Run docker compose up -d. Postgres, pgvector, Agent Hub, Data Service, Networks v3, Chat, Accuracy, and Portal all come up with sensible defaults.
Create the superadmin
The bootstrap script prompts for the superadmin email and a strong password. SSO can be configured next — but the local superadmin is your break-glass account.
Register at least one model
Point VDF AI at your existing OpenAI/Anthropic/x.ai key, an Ollama runtime on the same box, or your private endpoint. Mix and match later.
Build your first agent and Network
The Portal walks you through agent creation, an intent template, and a network. By the time the kettle is empty, your first call is logged in Live Execution Monitoring.
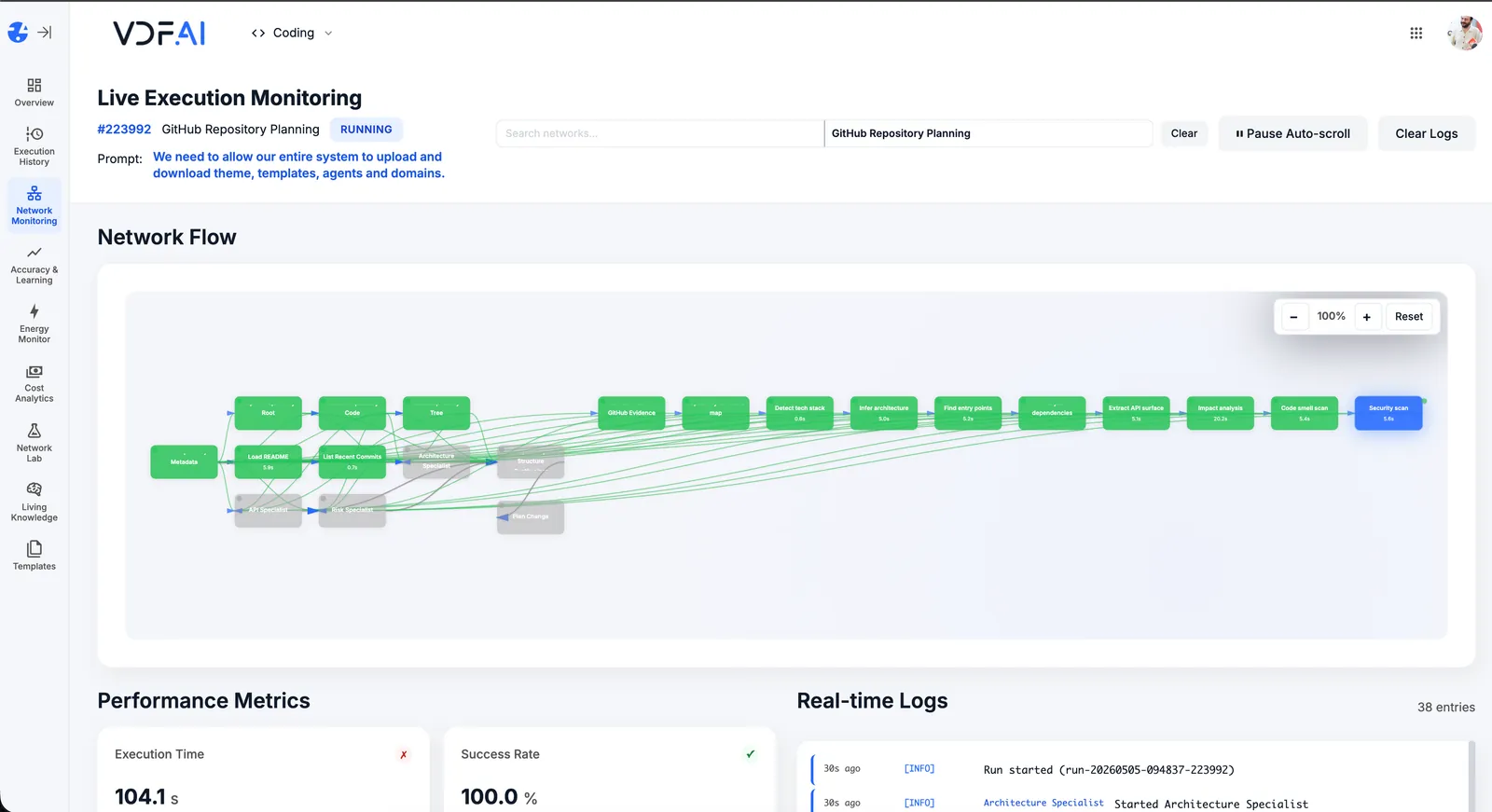
OUTCOMES
A working on-prem AI stack in hours, not months
from pull to live first agent on your own server.
free on the Sovereign tier while you evaluate.
on-prem — no external dependency for inference, retrieval, or storage.
SEEMR REFERENCE
Routing intelligence ships in the box
SEEMR is part of the standard install. Day 1 already includes the model governance, cost, and energy modes — they activate as you start running real traffic.
FREQUENTLY ASKED QUESTIONS
What teams ask before shipping this playbook
Can we install in an air-gapped environment?
Yes. Export the image bundle as a tarball from a connected machine, transfer, and load. No outbound connectivity required at runtime.
How do we connect our existing identity provider?
SSO via Azure AD, Okta, or Keycloak is supported. The bootstrap superadmin is for break-glass; production users come in via SSO.
What models can we register on day one?
Cloud (OpenAI, Anthropic, xAI, OpenRouter, DeepSeek), Hugging Face, Ollama, or your own custom endpoint. Mix them; SEEMR will route.
How is data persisted?
Postgres with pgvector for indexes and structured data; a file-store volume for documents and run artifacts. Both run in your control.
Is the 2-month free period really 2 months?
Yes. The Sovereign tier license is granted for two calendar months at signup, with no usage caps for evaluation purposes.
What support do we get during the free period?
A dedicated Slack channel with our solution engineering team, weekly office hours, and direct access to product engineers.
RELATED PLAYBOOKS
Continue with related VDF AI patterns



GET IN TOUCH
You Have Questions
Tell us what you’re trying to achieve—governed AI Networks, enterprise RAG, deep integrations, or on‑premise deployment. We’ll help you map the right architecture, security posture, and rollout path. If you’re moving beyond AI pilots and need scalable, auditable execution, reach out—our team is ready to help.